

EZF-005. AWS, Azure, GCP, Cloud agnostic offerings based on data type and needs; Virtualization vs Containerization; WebSockets. API Architecture; Python List Methods; Back-of-the-envelope estimation
Recap on system design for this week:
AWS, Azure, GCP, Cloud agnostic offerings based on data type and needs
Virtualization vs Containerization
WebSockets. API Architecture style
Python List Methods
Back-of-the-envelope estimation
1. AWS, Azure, GCP, Cloud agnostic offerings based on data type and needs
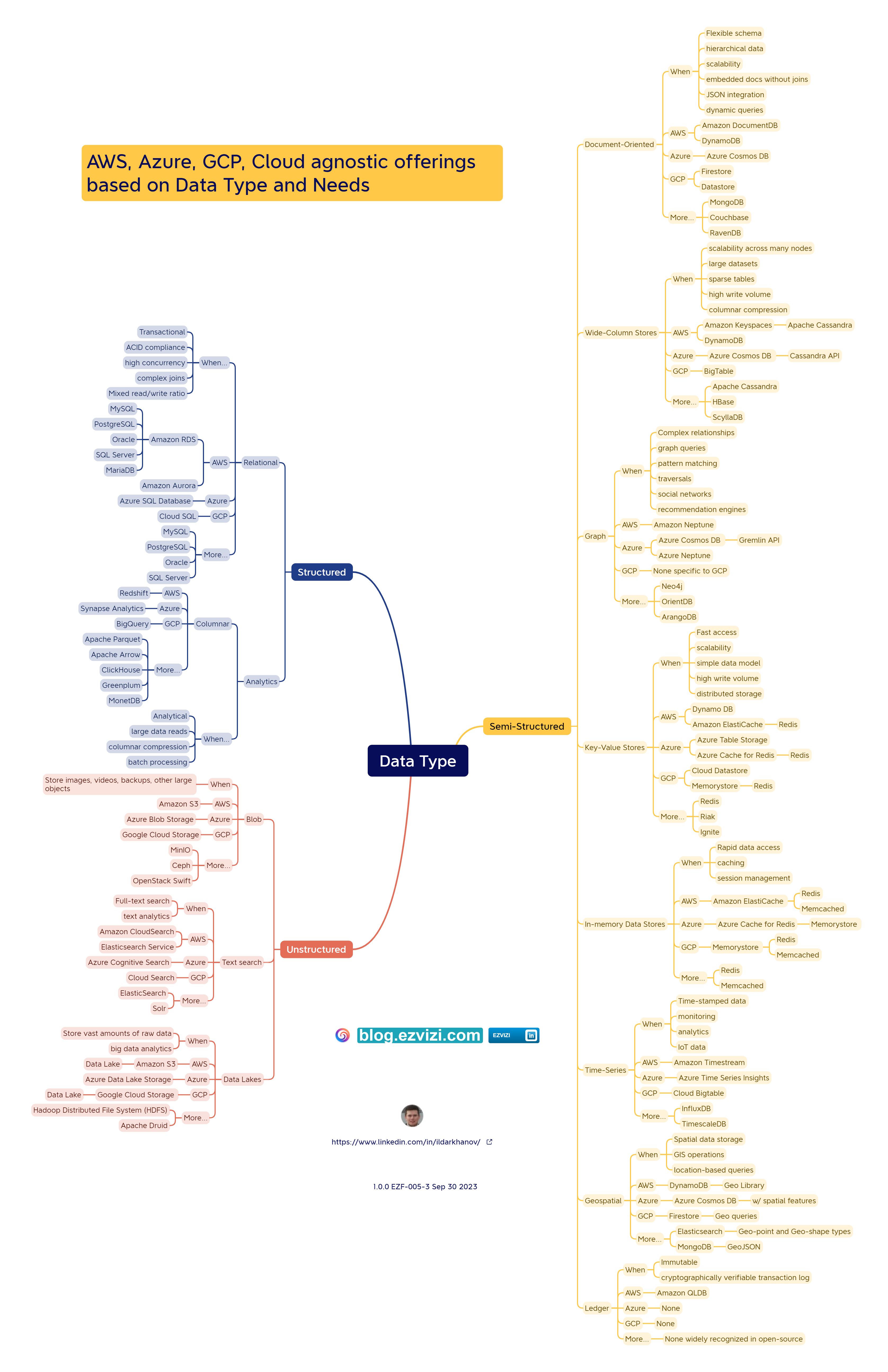
When selecting a database or data store, it's essential to consider the nature of your data. Structured data typically requires databases that can handle defined schemas and relationships. Semi-structured data, which might include formats like JSON or geospatial data, often benefits from more flexible database solutions. Unstructured data, such as text or images, might be best stored in specialized storage solutions or data lakes. Each major cloud provider, including AWS, Azure, and GCP, offers a variety of databases tailored to these data types. Additionally, there are cloud-agnostic options available for those seeking platform-independent solutions. For a comprehensive breakdown of offerings based on data types, please refer to the provided table.
2. Virtualization vs Containerization
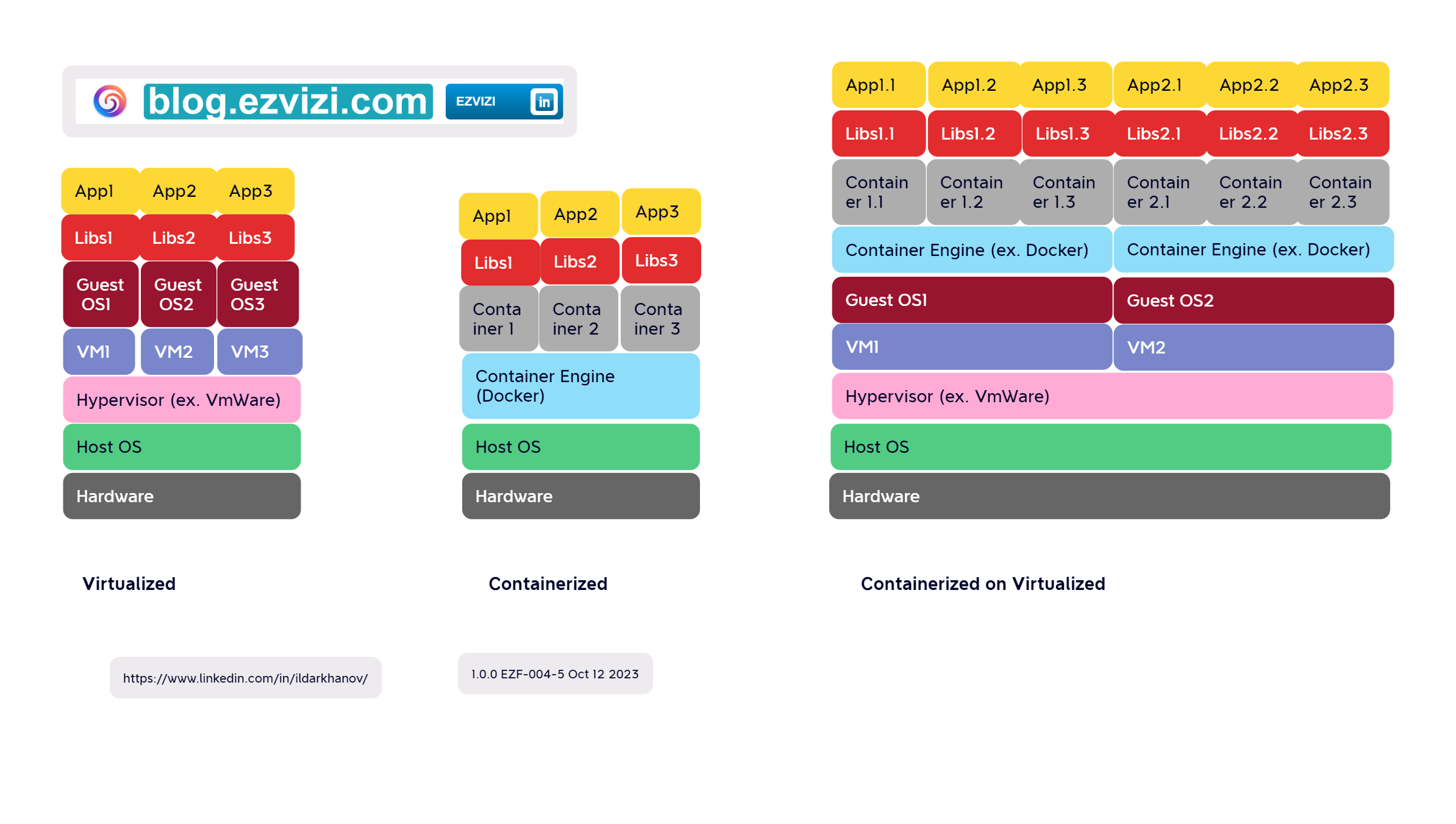
2.1. Virtualization:
🔹Level: Operates at the hardware level.
🔹Technology: Uses hypervisors (Type 1 like VMware vSphere, Microsoft Hyper-V or Type 2 like Oracle VirtualBox) to create and run virtual machines (VMs).
🔹Components: Each VM has:
- Its own full OS instance.
- A virtual copy of all the hardware that the OS requires.
🔹Isolation: VMs are fully isolated from each other.
🔹Resource Overhead: Generally, VMs have more overhead due to the duplication of full OS instances and emulated hardware.
🔹Use Cases: Ideal for running multiple instances of entirely different operating systems or different configurations of the same OS.
2.2. Containerization:
🔸Level: Operates at the OS level.
🔸Technology: Uses container platforms (like Docker, containerd, or rkt) to create and run containers.
🔸Components: Containers:
- Share the host OS kernel.
- Package only the application and its dependencies.
🔸Isolation: Containers are isolated from each other but share the same OS kernel.
🔸Resource Overhead: Containers are lightweight with minimal overhead since they share the same OS kernel and avoid hardware emulation.
🔸Use Cases: Ideal for microservices, scalable cloud-native applications, and situations where you want to maintain consistent environments between development, testing, and production.
2.3. Key Differences:
🟢Efficiency: Containers are generally more resource-efficient than VMs.
🟢Startup Time: Containers start faster as they don't need to boot an entire OS.
🟢Portability: Containers encapsulate dependencies, making them highly portable across different stages of development and even between cloud environments.
🟢Management Tools: Virtualization uses tools like VMware vCenter, while containerization has orchestration tools like Kubernetes.
While both virtualization and containerization allow for environment isolation, they differ in their approach, efficiency, and use cases. The choice between them depends on the specific needs of a project or infrastructure.
How do security concerns differ between containerization, which shares an OS kernel, and virtualization with separate OS instances?
❓ How do security concerns differ between containerization, which shares an OS kernel, and virtualization with separate OS instances?
3. WebSockets. API Architecture style
Ever wondered how your favorite chat apps or live trading platforms update so swiftly? The magic lies in WebSockets, an API architecture style enabling real-time, two-way communication. 🔄
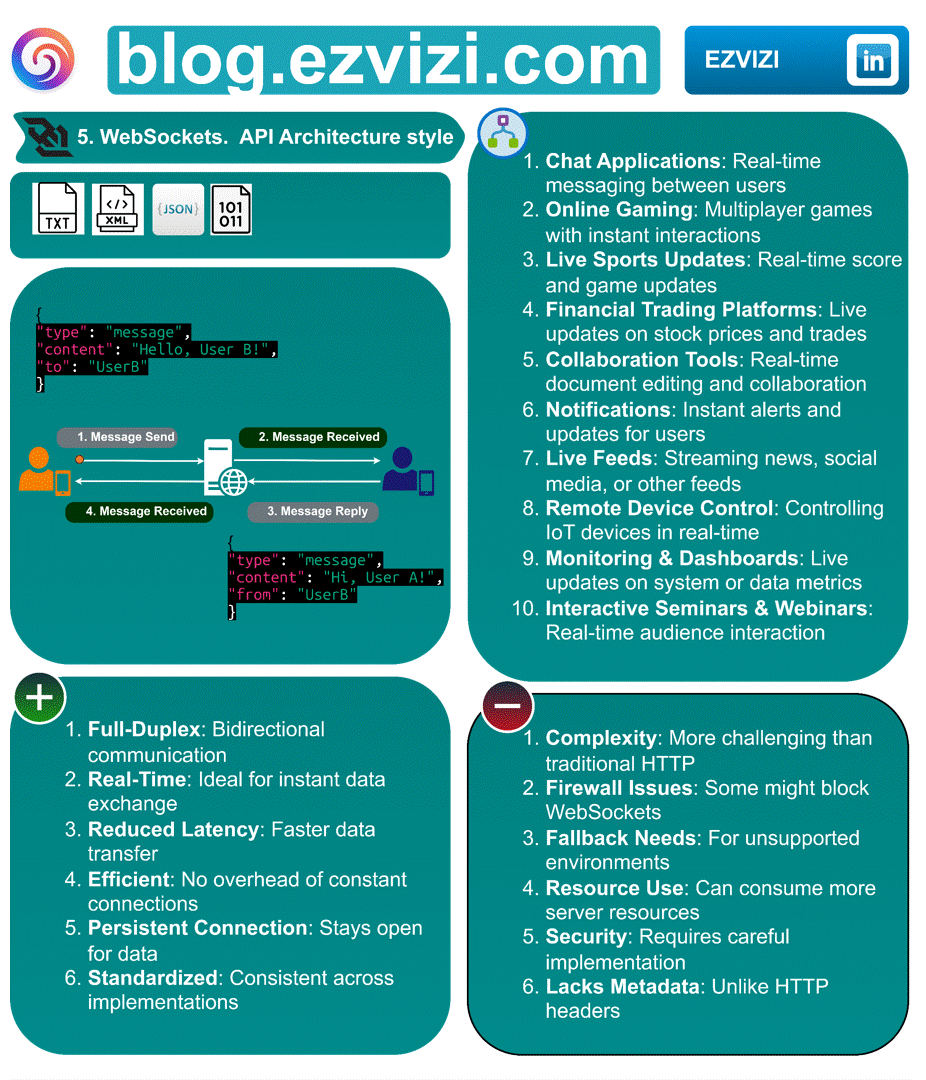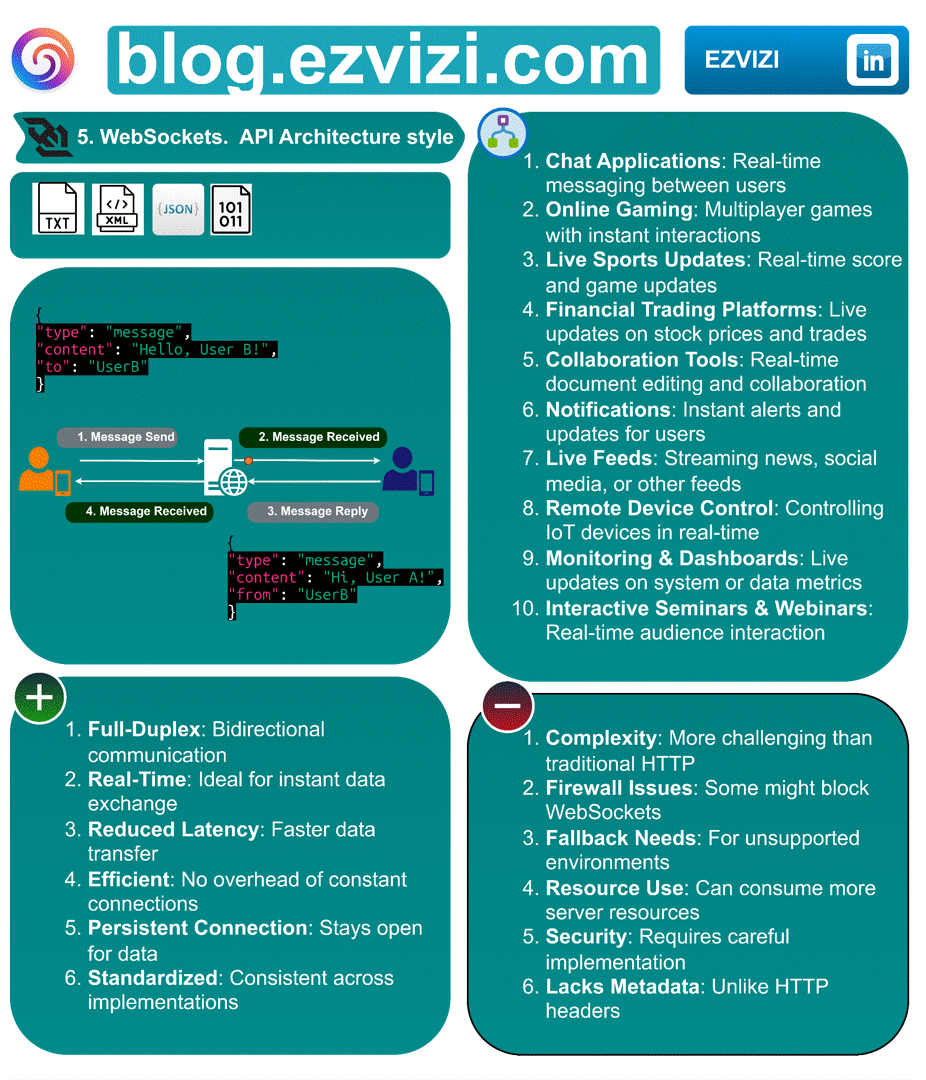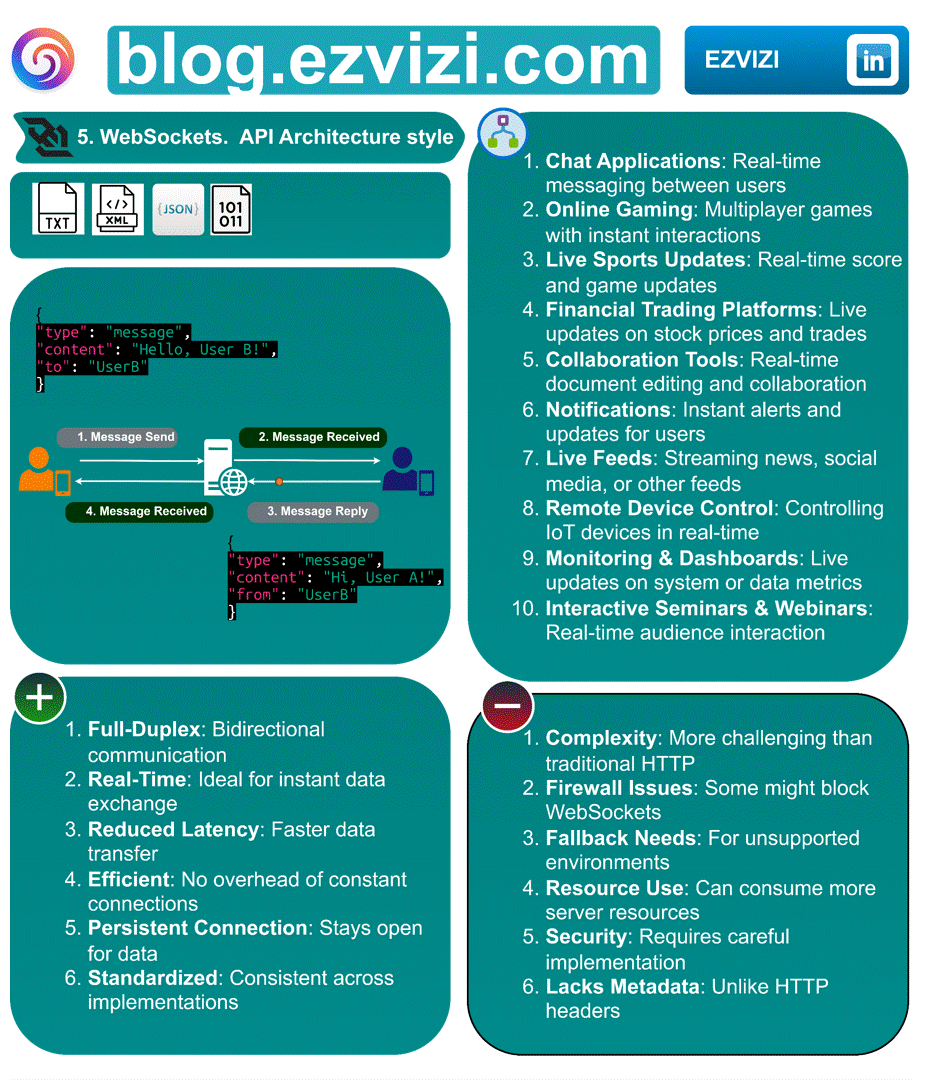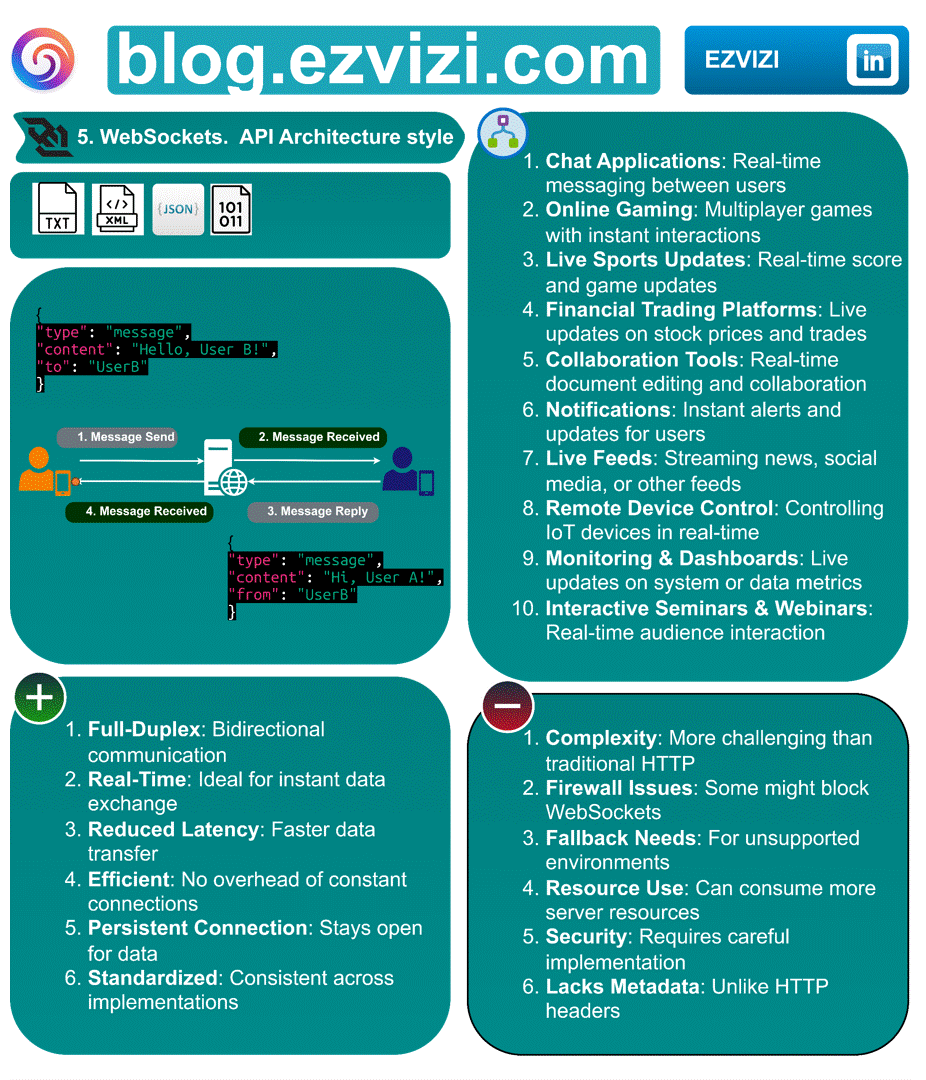
3.1. Message formats:
◉ Text
◉ Binary
◉ JSON
◉ XML
◉ Custom
3.2. Advantages:
✅ Full-Duplex: Bidirectional communication
✅ Real-Time: Ideal for instant data exchange
✅ Reduced Latency: Faster data transfer
✅ Efficient: No overhead of constant connections
✅ Persistent Connection: Stays open for data
✅ Standardized: Consistent across implementations
3.3. Disadvantages
❌ Complexity: More challenging than traditional HTTP
❌ Firewall Issues: Some might block WebSockets
❌ Fallback Needs: For unsupported environments
❌ Resource Use: Can consume more server resources
❌ Security: Requires careful implementation
❌ Lacks Metadata: Unlike HTTP headers
3.4. 📋 Use cases
◉ Chat Applications: Real-time messaging between users
◉ Online Gaming: Multiplayer games with instant interactions
◉ Live Sports Updates: Real-time score and game updates
◉ Financial Trading Platforms: Live updates on stock prices and trades
◉ Collaboration Tools: Real-time document editing and collaboration
◉ Notifications: Instant alerts and updates for users
◉ Live Feeds: Streaming news, social media, or other feeds
◉ Remote Device Control: Controlling IoT devices in real-time
◉ Monitoring & Dashboards: Live updates on system or data metrics
◉ Interactive Seminars & Webinars: Real-time audience interaction
❓ With the rise of real-time applications, WebSocket has become a go-to solution for many. How do you balance the benefits of persistent connections in WebSockets with potential scalability challenges?
4. Python List Methods

Understanding these list methods is essential for efficient data manipulation in Python:
1. 📌 append() - Adds an element to the end of the list.
2. ➕ extend() - Appends elements from another list (or any iterable) to the end.
3. ⬅️ insert() - Inserts an element at a specified position.
4. ❌ remove() - Removes the first occurrence of the specified element.
5. 💥 pop() - Removes and returns the element at the specified position. If no index is specified, it removes and returns the last element.
6. 🚫 clear() - Removes all elements from the list.
7. 🔍 index() - Returns the index of the first occurrence of the specified element.
8. 🔢 count() - Returns the number of occurrences of the specified element.
9. 🔤 sort() - Sorts the list in ascending order by default. You can also specify reverse order or a custom key function.
10. 🔁 reverse() - Reverses the order of the list.
11. 📋 copy() - Returns a shallow copy of the list.
❓ How do you find the index of a value's second occurrence in a Python list?
5. Back-of-the-envelope estimation
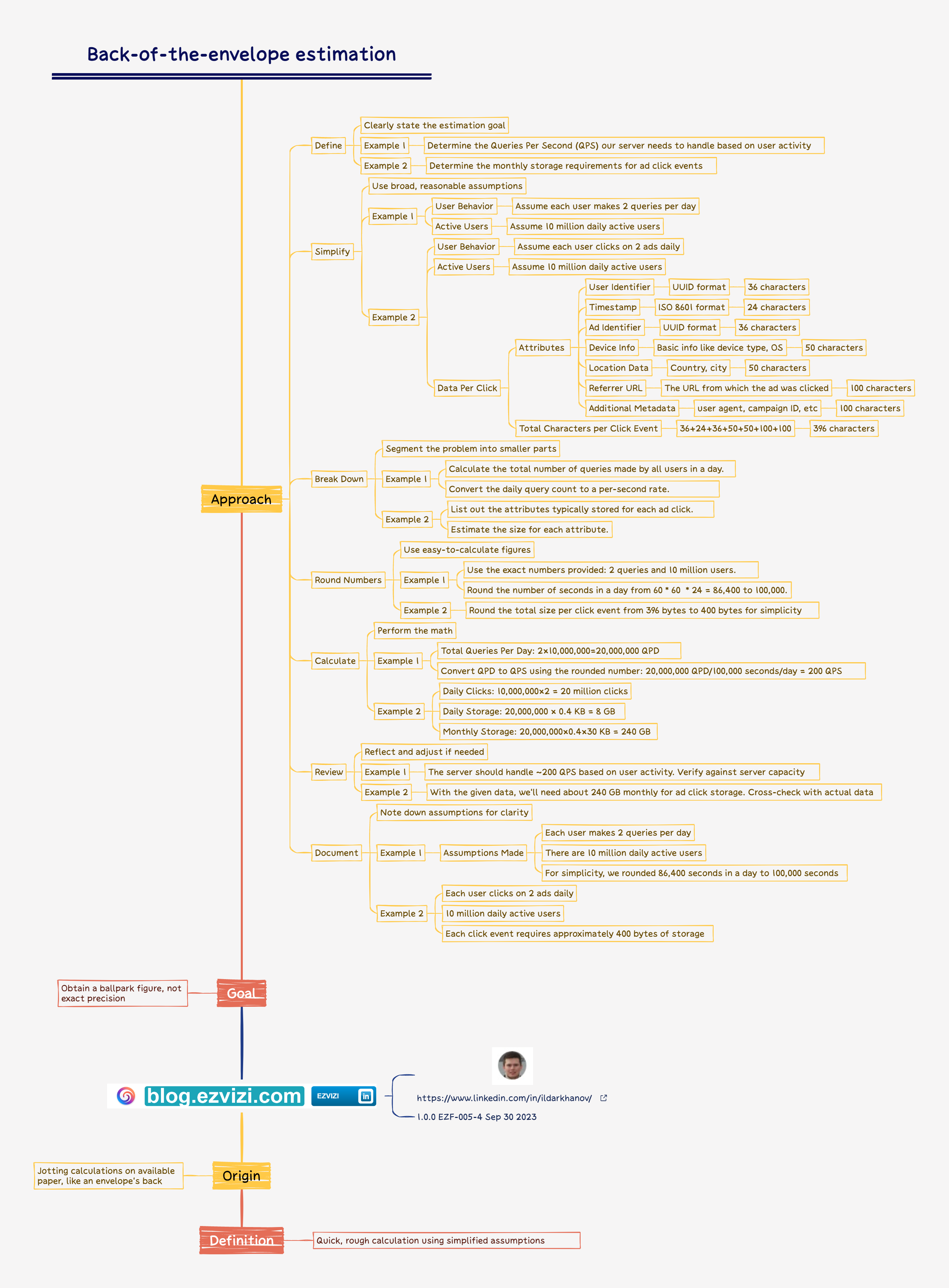
"Back-of-the-envelope estimation" refers to a rough calculation or estimation made quickly using simplified assumptions. The term originates from the idea of jotting down a quick calculation on any available piece of paper, such as the back of an envelope. The goal is to get a ballpark figure or order of magnitude, rather than an exact number.
Here's how you can approach a back-of-the-envelope estimation:
🔘 Define the Problem: Clearly state what you're trying to estimate.
🔘 Simplify Assumptions: Make broad assumptions that simplify the problem. These assumptions should be reasonable but don't need to be precise.
🔘 Break Down the Problem: Divide the problem into smaller, more manageable parts.
🔘 Use Round Numbers: Instead of using precise numbers, use rounded numbers that are easier to work with.
🔘 Calculate: Perform the calculation using the simplified assumptions and rounded numbers.
🔘 Review & Adjust: Reflect on the result. Does it seem reasonable? If not, adjust your assumptions and recalculate.
🔘 Document Assumptions: Always note down the assumptions you made, so you (or someone else) can understand the context of your estimation.
Example 1:
🔘 Define:
- Estimation Goal: Determine the Queries Per Second (QPS) our server needs to handle based on user activity.
🔘 Simplify:
-User Behavior: Assume each user makes 2 queries per day.
- Active Users: Assume 10 million daily active users.
🔘 Break Down:
- Calculate the total number of queries made by all users in a day.
- Convert the daily query count to a per-second rate.
🔘 Round Numbers:
- For simplicity:
- Use the exact numbers provided: 2 queries and 10 million users.
- Round the number of seconds in a day from 86,400 to 100,000.
🔘 Calculate:
- Total Queries Per Day: 2×10,000,000=20,000,000
- 2×10,000,000=20,000,000 QPD
- Convert QPD to QPS using the rounded number:
- 20,000,000 QPD/100,000 seconds/day = 200 QPS
🔘 Review:
The result indicates that the server should handle approximately 200 QPS based on the given user activity and rounded seconds. This value can be cross-checked with server capabilities and real-world data.
🔘 Document:
- Assumptions Made:
- Each user makes 2 queries per day.
- There are 10 million daily active users.
- For simplicity, we rounded 86,400 seconds in a day to 100,000 seconds.
❓ How would you use a back-of-the-envelope estimation to predict the number of cars passing through a busy intersection in a day, given only the traffic flow in one hour?
#systemdesign #softwareengineering #coding #dev #Webhooks #API #BackOfTheEnvelope #Estimation #SystemDesign #QuickCalculation #RoughEstimate #DesignAssumptions #InfrastructurePlanning #CapacityEstimation #SystemScaling #PerformanceEstimation #Relational #JSON #Geospatial #TimeSeries #Graph #KeyValue #BlobStorage #DataWarehouses #DataLakes #TextSearch #Ledger #InMemory #structureddata #SemiStructureddata #Unstructureddata #AWS #Azure #GCP #DataStorage #BigData #NoSQL #SQL #kubernetes #k8s #container #VMware