

EZF-003. GraphQL API Architecture style; Netflix - What it’s built on; Comparison of URI, URL, and URN; 27 Microservices Best Practices; Master-Slave Replication

Recap on system design for this week:
GraphQL API Architecture style
Netflix. What it’s built on
Comparison of URI, URL, and URN
27 Microservices Best Practices
Master-Slave Replication
1. GraphQL API Architecture style
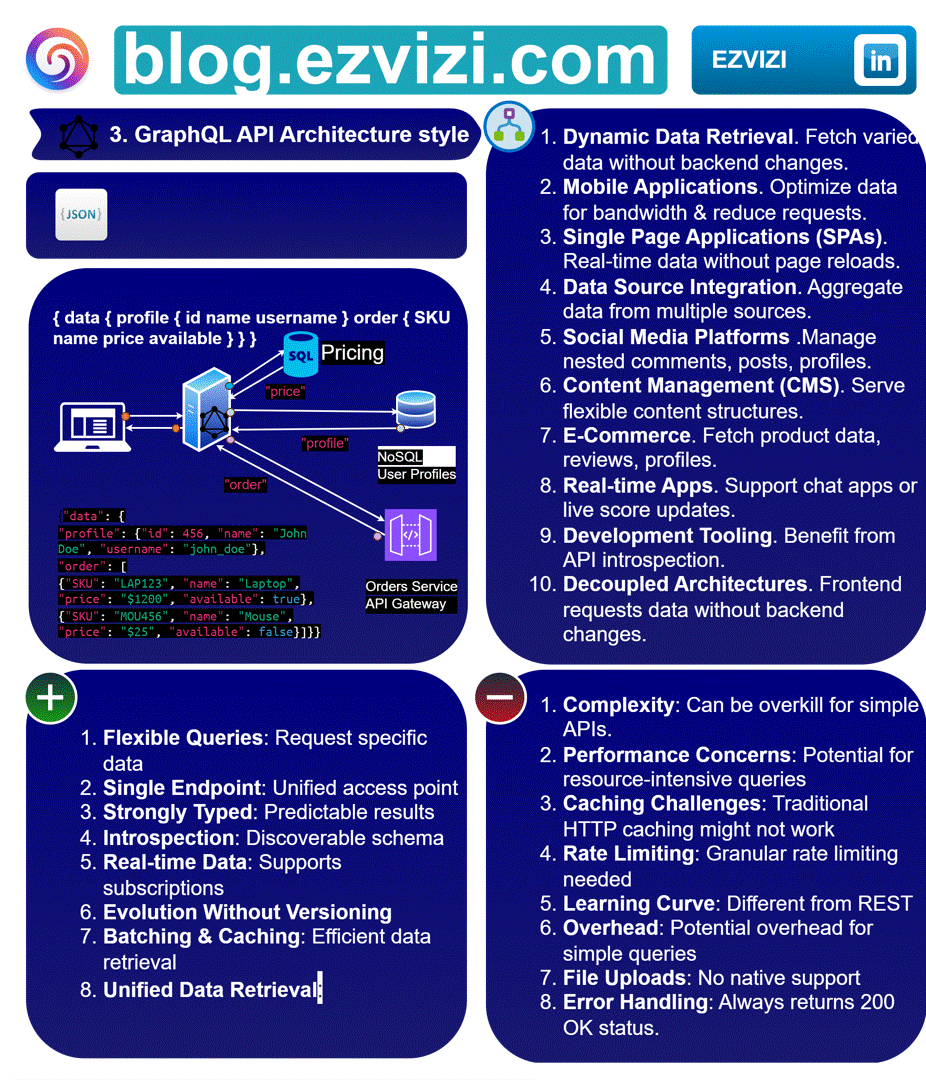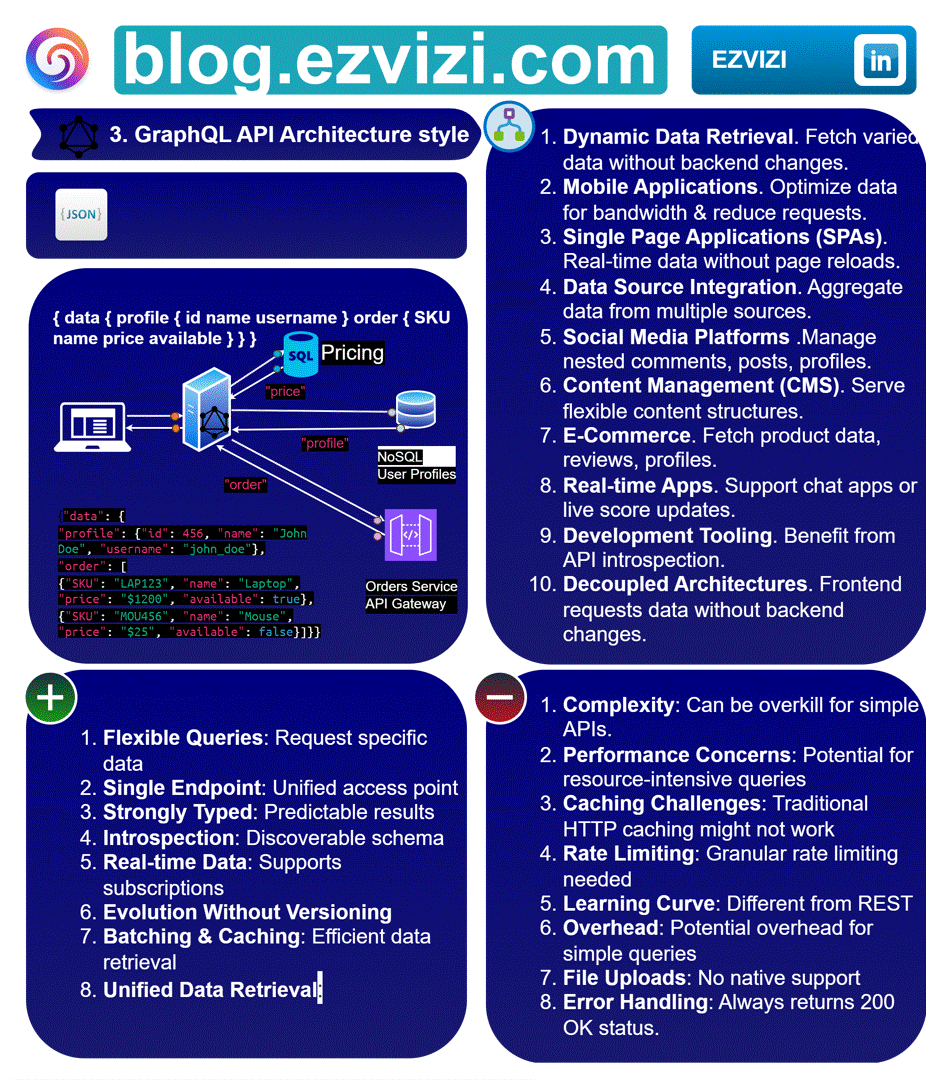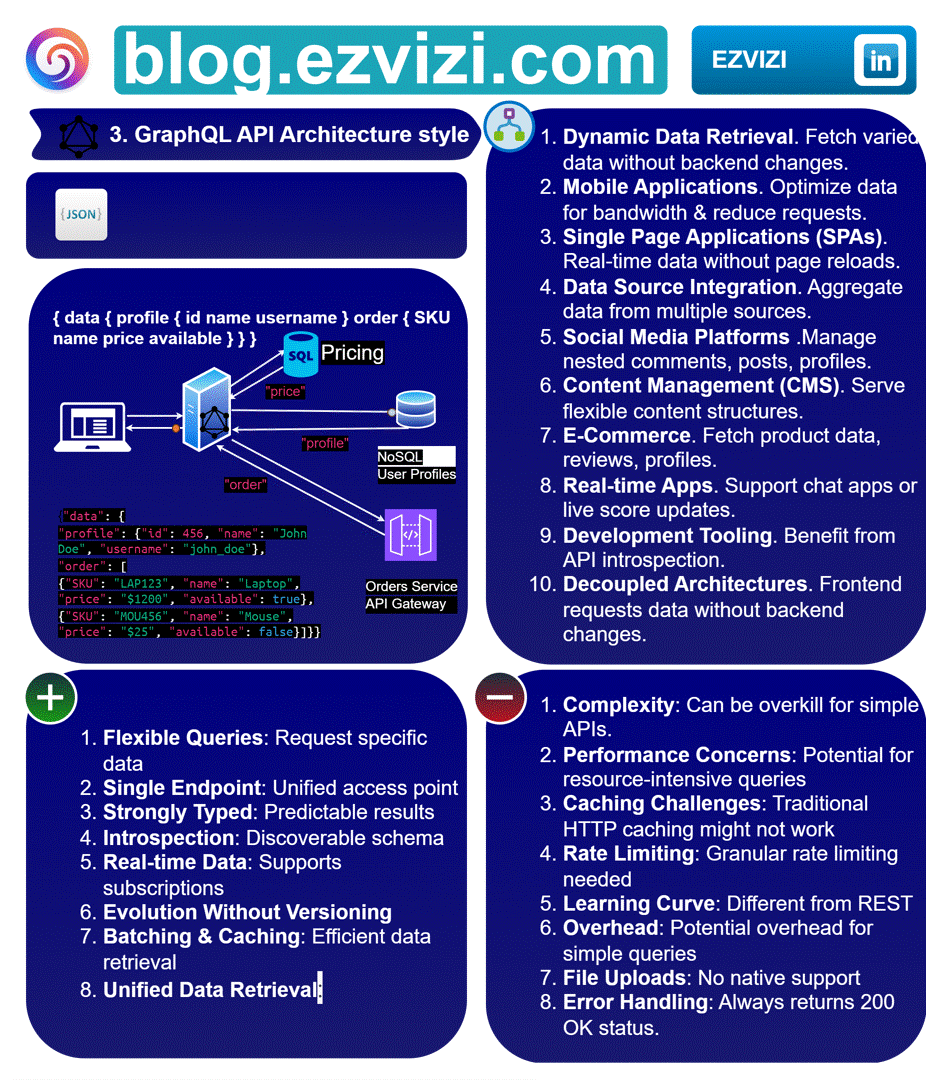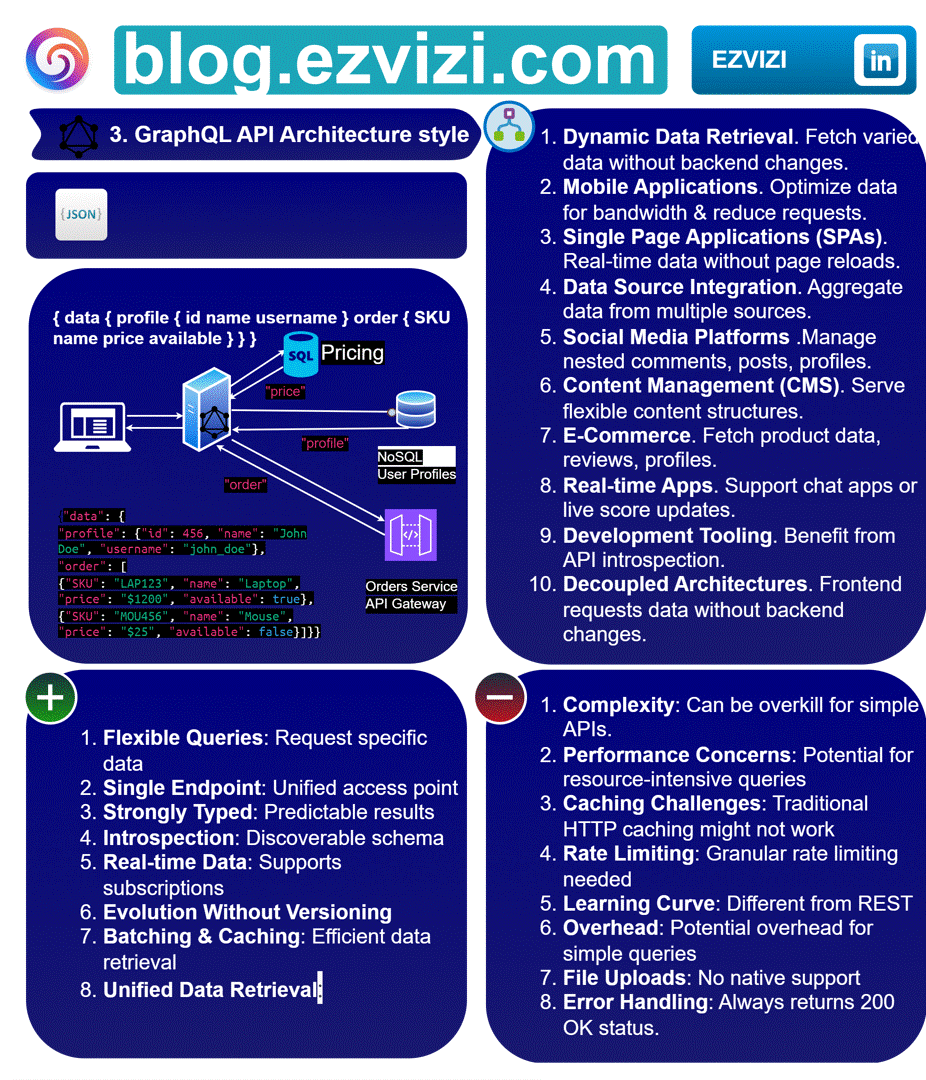
1.1. Message formats:
JSON
1.2. ✅ Advantages:
Flexible Data 📦: Request only needed data, reducing network load.
Strong Typing 🔍: Clear client-server contract via a defined schema.
Single Endpoint 🎯: One endpoint for all interactions simplifies API usage.
Real-time Updates ⚡: Subscriptions support live data reflection.
Introspection 🔮: Self-documenting APIs for easier discovery.
Declarative Fetching 📋: Describe data needs without backend specifics.
Batch & Cache 🚀: Combine requests and optimize caching.
Smooth Evolution 🌱: Add features without breaking existing ones.
1.3. ❌ Disadvantages
Complexity 🌀: Can be overkill for simple APIs.
Performance ⏳: Nested queries may slow response times.
Caching 🧩: Fine-grained queries complicate caching.
Rate Limiting 🚦: Trickier with a single endpoint.
Learning Curve 📚: New query language to master.
Over-fetching 🎒: Risk of requesting excess data.
Errors ❗: Ambiguous or partial failures.
File Uploads 💾: Not natively supported.
Overexposure 🔓: Potential data security risks.
1.4. 📋 Use cases
Dynamic Data 📱: Tailor data for different clients (web, mobile, IoT).
SPAs 🖥️: Efficient data fetching for Single Page Applications.
Real-time Apps ⚡: Push updates for chats, scores, stocks.
Microservices 🕸️: Unified data layer across services.
API Gateway 🚪: Intermediary between clients and backends.
REST Wrapper 🔄: Add flexibility to existing REST APIs.
Rapid Prototyping 🚀: Speed up development with introspection.
CMS 📄: Flexible content querying and management.
E-commerce 🛍️: Manage complex product and user data.
Social Aggregators 🌐: Streamline fetching from multiple sources.
❓ What API architecture style are you guys currently utilizing in your system?
2. Netflix. What it’s built on

Netflix has a complex and evolving tech stack that supports its massive global streaming service.
1. Frontend
1.1. Web: Node.JS (client side), HTML 5, JS, React
1.2. Mobile: Kotlin (Android), Swift (iOS)
Communication via Federated GraphQL
2. Backend.
2.1. Cloud Infrastructure: AWS - majority of Netflix's cloud infrastructure
2.2. Microservices Architecture: Microservices (1000+ microservices), Netflix ZuuL (API GW), Netflix Eureka (Service Discovery)
2.3. Data Storage & Databases
2.3.1. Relational databases: MySQL, CockroachDB
2.3.2. NoSQL databases: Cassandra, Amazon DynamoDB
2.3.3. Content/Streaming: S3, Elastic Transcoder
2.3.4. Search Engines: ElasticSearch
2.3.5. Caching: EVCache
2.4. Big Data & Analytics
2.4.1. Stream processing systems: Kafka, Flink
2.4.2. Batch processing systems: Apache Spark
2.4.3. Data warehousing solutions: Amazon Redshift, Snowflake
2.4.4. Data Visualization: Tableau
2.4.5. Real-time analytics: Druid
2.4.5. To enhance data performance: Iceberg
2.5. Machine Learning: TensorFlow
2.6. CDN: Netflix Open Connect
2.7. Networking
2.7.1. LBs: Amazon ELB, Netflix Zuul
2.7.2. Service Mesh: Envoy
2.8. Scripting & Automation: Python, Groovy
2.9. Incident Management: PagerDuty
3. DevOps.
3.1. CI/CD: Spinnaker, Jenkins
3.2. Configuration Management: Archaius
3.3. Monitoring & Observability
3.3.1. Time-series monitoring: Apache Atlas
3.3.2. Logging systems: ELK stack
3.3.3. Tracing tools: Zipkin
3.4. Resilience & Chaos Engineering: Chaos Monkey
3.5. Version Control: Git, GitHub
3.6. Infrastructure as Code: Terraform
3.7. Collaboration & Communication: Slack, Jira, Confluence
3.8. Build Automation & Dependency Management: Gradle
3.9. Enhance the build and release process: Nebula
4. Sources:
4.1. https://netflixtechblog.com/
4.2. https://aws.amazon.com/solutions/case-studies/innovators/netflix/
4.3. https://github.com/Netflix
❓Are there any components or technologies that need to be corrected?
3. Twenty-seven (27) Microservices Best Practices

Efficiently architecting, building, and maintaining microservices is vital to optimize both human and infrastructure resources. For successful microservice implementation, it's essential to adopt practices that ensure flexibility, efficiency, and scalability:
1. Independent Deployment and Scalability: Deploy and scale each microservice separately.
2. Domain-Driven Design: Model services based on business domains to ensure alignment with business capabilities.
3. Loose Coupling & High Cohesion: Minimize inter-service dependencies and group related functionalities.
4. API Versioning & Backward Compatibility: Ensure older versions of services or clients continue to function with newer releases.
5. Service Discovery: Leverage solutions like Consul or Eureka, allowing dynamic contraction and expansion without a central agent.
6. Centralized Configuration: Manage configurations across services centrally.
7. Health Checks: Implement health endpoints for monitoring service health.
8. Distributed Tracing: Trace requests across services for diagnostics.
9. Circuit Breakers & Automatic Retries: Ensure systems are fault-tolerant and can handle service interruptions.
10. Data Consistency: Ensure data consistency across services using patterns like Saga.
11. Centralized Logging: Centralize logs for easier debugging.
12. API Gateway: Route requests and handle authentication centrally.
13. Authentication & Authorization: Implement access restriction protocols to ensure only authentic users access services.
14. Rate Limiting & Request Caching: Prevent excessive requests and reduce load on services.
15. Database Per Service: Dedicate a database to each service for decoupling.
16. Event-Driven & Asynchronous Architecture: Use message queuing services like RabbitMQ and leverage asynchronous protocols for better performance.
17. Automated Testing: Implement comprehensive testing for each service.
18. CI/CD & DevOps Practices: Automate processes and ensure development teams own and support changes from development to end-of-life.
19. Containerization & Orchestration: Use Docker and Kubernetes for deployment consistency.
20. Single Responsibility Principle: Each service should cater to one business capability.
21. Statelessness: Design microservices to be stateless for scalability.
22. Security: Ensure data encryption, API, and network security.
23. Code Maturity: Keep code within a service at a similar maturity level.
24. Separate Builds: Each microservice should have its own build and deployment pipeline.
25. Micro Frontends: Develop and deploy frontend components independently.
26. Documentation: Keep API documentation up-to-date.
27. Monitoring & Alerts: Use tools like Prometheus for monitoring and set up alerts.
28. Backup & Disaster Recovery: Regularly backup data and have recovery processes in place.
❓ Which best practices are you implementing for your microservices architecture?
4. Comparison of URI, URL, and URN.

Comparison of URI, URL, and URN.
4.1. URI (Uniform Resource Identifier)
- syntax: scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
- Purpose: To identify a resource
- Persistence: Can be either persistent or transient
- Definition: A generic term for any type of name or address referring to a resource.
Example: mailto:ezvizi.com@gmail.com?subject=Ad Placement Request?&cc=ezvizi.com@gmail.com&bcc=ezvizi.com@gmail.com
4.2. URL (Uniform Resource Locator)
- syntax: scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
- Purpose: To locate a resource
- Persistence: Typically transient; can change if the resource moves
- Definition: A specific type of URI that describes where a resource is located and how to access it.
Example: https://user:password@www.ezvizi.com:8080/products/page1?item=123#section2
4.3. URN (Uniform Resource Name)
- syntax: urn:<namespace-identifier>:<namespace-specific-string>
- Purpose: To name a resource uniquely
- Persistence: Meant to be persistent; doesn't change even if the resource's location changes.
- Definition: A specific type of URI that provides a persistent identifier for a resource without implying its location or how to access it.
Example: urn:isbn:0451450523
❓ Can a URI be both a URL and a URN?
5. Master-Slave Replication

The master handles both reads and writes, sending write replicas to its slaves, which are read-only. Slaves can further replicate in a hierarchical manner. If the master fails, the system shifts to read-only until a slave becomes the master or a new master is set up.
🌟 Advantages:
✅ Reading from slaves doesn't impact the master.
✅ Backups don't heavily affect the master.
✅ Slaves can resync to the master without downtime.
😕 Disadvantages:
❌Additional hardware and complexity due to replication.
❌All writes must go through the master.
❌Potential data loss and downtime if the master fails.
❌More read slaves can lead to increased replication delays.
❓ In a master-slave replication setup, if the master becomes isolated from the network due to a network partition but remains operational, and one of the slaves is promoted to a master, what strategies can be employed to handle data inconsistencies when the original master is reconnected?